What's up?

Houses |
While RSS and Atom are a great way to stay up to date on what is published around the web, I think the feed-centric approach taken by most feed readers is suboptimal. For some feeds I want to read everything that is posted, but for others I want to read only those few posts which are about subjects I care about, or by authors I like particularly. Another problem is that some feeds (for example those of newspapers) have hundreds of posts every day. Staying on top of that is just too much manual effort.
So, what to do?
To handle this, I wrote my own little RSS reader in Python, called "What's up". So far I've been using it for about two years, and for most of that time I've used no other RSS reader, or even thought about switching. Over the time that I've used it I've marked 22,000 URLs as read in the reader.
Implementation
I came up with an approach that has just a single list of posts, regardless of which feeds they come from, where posts get an automatically computed relevance score, decreasing with the age of the post. (This was more than a little inspired by Reddit.)
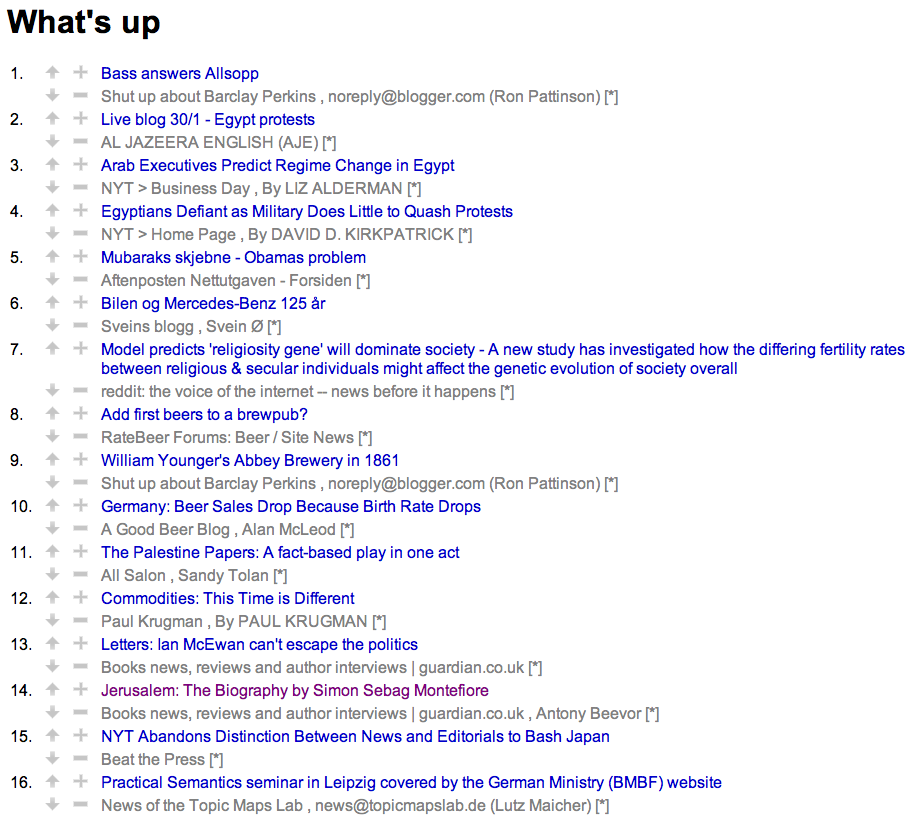
Screenshot |
The difficulty, of course, is to compute a relevance score given nothing more than the information in an RSS feed. To do this, I decided to use an approach that's common in spam filters (such as SpamBayes). Basically, the text in the post title and summary gets broken into tokens, and each token is assigned a probability between 0 and 1. To begin with the probability is 0.5, but each post in the list can be voted up or down with the up and down arrows. When the user does that, the probability of each word in the post is adjusted accordingly. (The minus button is used to remove a story without voting on it.)
To turn the list of probabilities into a relevance score, I simply use Bayes' theorem. To handle the age of posts I divide the relevance score by the logarithm of the number of seconds since the post was published.
How it works
Overall it actually works surprisingly well. All sports news, celebrities twaddle and so on gets filtered out. Stories about beer, airlines, interesting technology, and so on rise up to the front page magically. Some feeds have many different authors, and in these cases, stories by the authors I'm keen to follow rise above those by the others. With 137 feeds in the reader, I get a nice mix of things from different sources.
Unfortunately, it doesn't work perfectly. The biggest problem is how little metadata there is in the feeds, and how poor it is. Many feeds, such as newspapers, don't list an author, even though a byline is given in the article. For those that do provide an author, there's often weird formatting in the field, which tends to change randomly over time. Many escape special characters twice, causing a mess in the data. The date formats are a total mess. Many feeds include just a short title and a very short summary in the feed, leaving the tool almost nothing to work with. In many cases, the tool gets nothing more than about 10 words. Not much of a basis for deciding if the post is interesting.
One blog post about a pub to pub round in Manchester got filtered out because the short paragraph given said nothing about beer or pubs, but did mention Manchester quite a bit. Of course, news stories including the word Manchester are mostly about Manchester United, and so the score for that particular word is very low.
Here's an example of a deeply uninteresting story, and how it's rated:
Fawcett swimsuit given to museum - BBC News
Late actress Farrah Fawcett's trademark red swimsuit, which she wore in a popular 1976 poster, is being donated to Washington's Smithsonian museum.
Apart from the time and URL, this all the useful information we have about the story. It's not a lot to go on.
After breaking up the text (and URL) into tokens, this is what we get:
given : 0.418181818182, wore : 0.375, farrah : 0.5, poster : 0.590909090909, museum : 0.58064516129, museum : 0.58064516129, trademark : 0.545454545455, donat : 0.5, actress : 0.294117647059, swimsuit : 0.5, swimsuit : 0.5, late : 0.407894736842, smithsonian : 0.5, washington : 0.545454545455, popular : 0.602739726027, fawcett : 0.5, fawcett : 0.5, red : 0.289719626168 url:rss : 0.424242424242, url:www.bbc.co.uk : 0.333333333333, url:int : 0.428571428571, url:go : 0.424242424242, url:new : 0.354838709677, url:new : 0.354838709677,
Many of the terms, like Fawcett's name, "swimsuit", "Smithsonian" and so on are all at 0.5, because they are unknown. A few get a mildly positive score, like "poster", "museum", "washington", "popular", and so on. What kills the story is the negative terms, particularly "actress", but also "wore", "red", and "given". Together with all the negatively rated URL tokens, this is enough to bury the story. It gets a word probability score of 0.018 (on a scale from 0 to 1), which is very low.

Road |
The code
The actual code is a bit of a mess. It's written in Python based on web.py (using the built-in templates). It runs as a server on my laptop, and I access it with a browser at localhost:7000. Underneath is an RSS- and Atom-reading library I wrote, plus some NLP code from the prototype I wrote of the Ontopia autoclassifier. This is all rather loosely cobbled together with bits of chicken wire and chewing gum, but actually works and doesn't crash much.
The CPU usage when recalculating points is quite high, and sometimes the UI hangs for a while during recalculation. The memory usage is also substantial: right now, for 3200 posts, it uses 140 MB of memory. (Update: 24 hours later, with 4200 posts, it uses 160 MB.)
Still, it works, which is the main thing for me. And I'm quite pleased with the basic concept.
Update: Because of the interest in this code on Reddit, I put the code into a Google Code project. Documentation etc will follow.
Similar posts
Bayesian identity resolution
Stian Danenbarger has been telling me for a while about entity resolution (as he and many others call it), or identity resolution (as Wikipedia calls it)
Read | 2011-02-11 13:23
Experiments in genetic programming
I made an engine called Duke that can automatically match records to see if they represent the same thing
Read | 2012-03-18 10:06
The applications of SDshare
Graham Moore a few years ago came up with the idea of publishing changes to topic maps using Atom, and a CEN project has now developed and published a specification for it called SDshare
Read | 2010-11-21 14:29
Comments
marten marteria - 2011-02-03 15:10:35
This is a great project. I wish I could programm as good as you!
Isn't it possible to exclude certain (stop)words? NLTK comes to mind. You could even balance the rating of synonyms out - if that makes any sense regarding the rating-system.
Lars Marius - 2011-02-03 15:40:03
> I wish I could programm as good as you!
It's kind of you to say that, but please remember that you haven't seen the code. :-)
> Isn't it possible to exclude certain (stop)words?
The code already does that, because autoclassifier that it's based on can do that. It also does stemming.
If you compare the input text in the example with the word vector below, you'll note the absence of "which", "the", etc.
> You could even balance the rating of synonyms out - if that makes any
> sense regarding the rating-system.
This is much harder than it sounds, because it requires you to know what are true synonyms. If "plane" appears in the text, is that a synonym with "level" or "aircraft"?
Robert Cerny - 2011-02-03 16:02:31
Sounds cool. One remark: The false positives and the false negatives, e.g. the Manchester story, indicate IMO a measure of how explicit the story is (for you). The Manchester story was given a low score because some important keywords were not explicitly mentioned. You could figure out the true value of the story by drawing conclusions with the help of your otherwise acquired knowledge. A false positive might as well be initially mistaken by a human reader as interesting. Again only the access of out-of-band information makes it possible to interpret the message correctly. In both cases the news snippet must be more difficult to process cognitively by the person which parametrized the system.
Lars Marius - 2011-02-04 03:03:12
Robert: It's true that human readers would not always perform better than the tool, and that sometimes the tool does better than human users. A major underlying cause (and problem) is that (usually) the tool doesn't have access to the entire article.
I've thought about following the link and downloading the story to get a more complete data set to work with, but the trouble is that most real web pages contain a lot of garbage text in addition to the story. I have some ideas for how to automatically extract just the real text (and not all the menu bars, navigational links, "related stories" and so on), but haven't done more than a trivial experiment so far.
Patrick Durusau - 2011-02-04 05:52:08
If you are successful at filtering everything but "...the real text..." that could be the basis for a very cool web browser.
As you remember, in the very earliest days of the web, users were supposed to be in charge of how content displayed, on their computers.
Sigh, seems like long ago and far away.
Would be interesting to have a subject service that identifies advertising and pushes that out to browsers so ad content, popup and otherwise could be filtered out from any display.
Edward O'Connor - 2011-02-04 13:39:37
I'm surprised to read that you wrote your own Python RSS & Atom parsing library. Is there a particular reason you didn't use the Universal Feed Parser?
Lars Marius - 2011-02-05 06:43:34
Patrick: That is an interesting idea, and one that hadn't occurred to me. Hmmm.
Edward: Two reasons. One being that I wasn't aware of the UFP. Maybe I should switch to that and get rid of some of the code. The other was that I already had an RSS parsing library from the around 2000 which I just reused.
heimo hänninen - 2011-02-07 15:27:52
Good stuff. When will it run on Android? :-) But seriously, I feel the paiin of feed glut too. Itreresting to see that your app does a good job even without more sophisticated linguistic analysis. Could make it learn by allowing reader's feedback to promote or dentote future results?
Lars Marius - 2011-02-07 15:43:27
Heimo: It does use reader feedback now. That's how it arrives at the probabilities for the various words. When you first start it all words (and all authors and all feeds) are rated at 0.5. When you vote a story up the score for the author, the feed, and all words in the story are incremented (to 0.54545454...). As you vote on more stories the votes accumulate and you get a more useful system.
But in the beginning the system does no more than rank stories by which are the newest. :)
Tobias Brox - 2011-02-11 05:21:03
I noticed the BBC example included "entertainment" in the URL, but there was no mentioning of it in the tokens. "entertainment" in the URL should certainly give it a low rating?
Lars Marius - 2011-02-11 05:56:23
Tobias: usually the last part of the URI contains the ID of the post, and to avoid getting huge numbers of garbage tokens in the data I strip out the last part of the URI (after the last /). So that part got stripped out.
I agree that 'entertainment' here indicates a category, and so over time probably it would have gotten downrated enough to get a low score.
Basically this is due to the somewhat primitive URI tokenizer I'm using. It could certainly be improved.