How to write a TM/XML deserializer
The TM/XML syntax is easy to understand for humans, and easy to process with XSLT, but seeing how to write a TM/XML deserializer is not trivial from the spec. However, once you know how to do it it's actually quite straightforward, so I thought I'd document the approach that I took here in case anyone else wants to have a go at this.
If you do try to implement a deserializer, let me know, and I'll send you my TM/XML test suite to help you verify that you've gotten it right. I'll also happily answer questions about how to interpret the paper.
Background
The best approach to take is to use an event-based parser API like SAX, and not to try to do this with the DOM or XPath. This way you can handle documents of any size, and it's also a lot faster since you don't have to build the full document tree before you start.
One thing that's quite tricky to do is to ensure that the document you are reading is correct according to the schema, since the schema is so generic and free-form. I recommend solving this by using a RELAX-NG validator in your tool. Just pass the events off to it, and let it validate that the document is actually correct. That way you don't have to bloat your code with tons of tests verifying at each step that the user didn't do one of the gazillion things that are not allowed.
The trickiest part of implementing a TM/XML importer on SAX is to know where in the schema you are at each point in the document. To put it another way, when you find a new element, how do you tell if it's a name, a topic, an occurrence, or a role? You can't tell from the element type names, so you really need to be careful about tracking the context. Fortunately, as you'll see there is an easy way to do this.
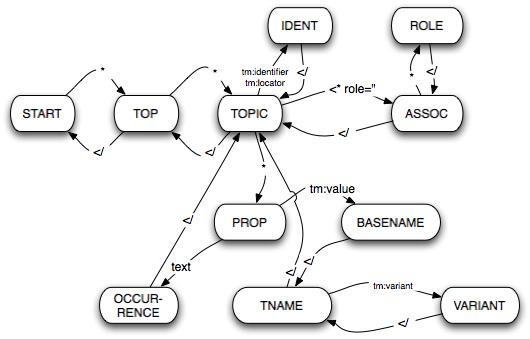
The only thing you need to do is to have a variable called state in your event handler. The value of this variable will tell you where you are at any given point. So when you receive a new start or end element you can work out what to do with it from the state and then work out where to go to next. The easiest way to capture what is going on is with a finite state automaton, which you'll find a nice diagram of below.
The automaton
The automaton may look big and scary, but it's actually dead simple. You start at the START node, and follow the arrow that matches the next start/end element event. That's it! If you do that, you'll always know where in the structure you are, and based on that you'll also know what to capture and what to do with it.
The automaton |
The START node is where you begin; in this state you are outside the document element. At this point, you don't do anything, until the first start element shows up. At that point (as shown by the "*" arrow) you move to the TOP state. This means that the start tag you are seeing is the one for the topic map itself, and so you need to handle the reifier attribute on that element. Beyond this there is no need to do anything.
In the TOP state any start tag that you see will be that of a topic, and this takes you to the TOPIC state. If you see an end tag, it means you're done with the entire document, and you go to START. (This may seem strange, but it's consistent with the "start" button in Windows, which you use to shut down the computer. :)
In the TOPIC state you are inside a topic element, and the next thing you see will be some property of the topic. The labels on the arcs going out of TOPIC tell you what to do. If you see tm:identifier or tm:locator it's easy to know what to do, and likewise if the element has a role attribute. Otherwise you go to PROP.
In the IDENT state you just capture the element content and add it as the corresponding type of identifier on the current topic. That's all.
In the ASSOC state you are inside an element representing an association. If it's n-ary you will be seeing role elements, otherwise you'll just see an end tag. The ROLE state should be obvious.
In the PROP state you know that you've either seen a topic name or an occurrence, but you don't yet know which. If you see text (or PCDATA), it means you are in an occurrence, and we go to the OCCURRENCE state, but if you see a tm:value element, it means you are in a topic name (and go to TNAME).
The rest, I think, is kind of self-explanatory. (I assume people will let me know if I'm wrong about this.)
An example
It will probably help to see an example in order to understand how this works. Below is the "puccini" topic, exported from the Italian Opera topic map in TM/XML syntax, with XML comments added showing the current state at each point in the file. (For simplicity it has just one name, one occurrence, and one association.)
<!-- START -->
<topicmap>
<!-- TOP -->
<music:composer id="puccini">
<!-- TOPIC -->
<tm:identifier><!-- IDENT
-->http://en.wikipedia.org/wiki/Puccini</tm:identifier>
<!-- TOPIC -->
<iso:topic-name scope="basename:short-name">
<!-- PROP -->
<tm:value><!-- BASENAME -->Puccini</tm:value>
<!-- TNAME -->
</iso:topic-name>
<!-- TOPIC -->
<opera:bibref><!-- PROP -->Sadie, Stanley (ed): "Puccini and
His Operas", Macmillan (London, 2000)<!-- OCCURRENCE
--></opera:bibref>
<!-- TOPIC -->
<biography:exponent-of
scope="psi.ontopia.net:music"
role="psi.ontopia.net:person"
topicref="verismo"
otherrole="opera:style">
<!-- ASSOC -->
</biography:exponent-of>
<!-- TOPIC -->
</music:composer>
<!-- TOP -->
</topicmap>
<!-- START -->
That's it. I hope this is useful for those who want to write TM/XML deserializers. If any such people ever show up, that is.
Similar posts
TM/XML
The design of TM/XML, first heard of at TMRA'05, has now at long last been finalized, and the paper about it sent off to the publishers
Read | 2005-12-03 16:35
Extracting fragments with TM-Views
Last time I wrote about how I used OSL to extract a fragment from a topic map
Read | 2005-11-30 23:49
Why XTM 2.0 is different from 1.0
Many people have asked what the changes between versions 1.0 and 2.0 of XTM are, and what the rationales for the various changes are
Read | 2006-12-16 19:17
Comments
Lars Heuer - 2006-08-02 19:32:37
Interesting article. I've begun to work on an TM/XML de-/serializer ontop of TMAPI for my TMRAP impl. I hope I find enough time to work on it again and to publish it (maybe August?!?). Time is always the limiting factor. :(
Lars Marius - 2006-08-02 20:09:31
I'd be very happy to see you publish that, I must say. I'll put together a release of the test suite for you later today. And, yes, time is the problem. Always.