TMRA'05 — first day
This is a semi-live report from the first Topic Maps conference: TMRA'05 in Leipzig.
The very first person to speak is Lutz Maicher, who introduces the workshop, and welcomes everyone to Leipzig and the conference. He says that the post-proceedings (containing all the papers below) will be available from Springer in 5-6 months. He then introduces Jack Park, and hands over to him.

Jack Park (apologies for the eyes) |
Jack Park is the keynote speaker, with a talk titled "Topic Mapping: A View of the Road Ahead". He starts by emphasising that he takes a personal view in this talk. The key theme is what he calls "relational thinking", which is developed by means of biological cells, mustard clocks (no, not a typo), and other unexpected topics.
To Jack, creating a topic map is modelling knowledge. He describes models as abstractions or representations, and sees the goal as being to bridge the gap between computer models and mental models. He quotes Robert Rosen, who sees the relation between the model and reality as one of encoding and decoding, and where inference on the model is meant to mirror causality in reality.
He put forward what he called "a modest proposal", which was to marry Topic Maps to Conceptual Graphs. He's using a tool called the Amine PLATFORM to show the potential benefits he sees to his. Amine is written in Java, and contains a Prolog interpreter "and all the goodies that come with Conceptual Graphs".
He showed how a simple Conceptual Graph can easily be expressed as an association in a topic map, then went on to nested Conceptual Graphs, which can also be expressed reasonably directly in Topic Maps. His claim is that although this works, a Conceptual Graph is a directed graph, a topic map is not, and therefore existing graph tools for Conceptual Graphs cannot be used with Topic Maps.
He closes with a slide ending "if you aren't steaming angry now, you didn't listen to this talk. :-)" Well, in that case I guess blogging distracted me enough to keep me calm. :)
Well. If the above doesn't really hang together, that's my fault, and not Jack's. I now know why attempts at blogging conference talks in real time usually come out as rather confused retellings of the original talks. This is actually quite hard to do. Sorry about that. I hope I'll get better at this as the day progresses.
Concept Glossary Manager
Jakub Strychowski (of rodan.pl) on ICONS, Intelligent CONtent management System, which is the result of an EU project with 7 partners, from January 2002 to April 2004. One of the components is the Concept Glossary Manager, which can store Topic Maps. CGM contains an engine, a navigator, a server, an editor, and a TouchGraph-based visualization applet. Sounds quite similar to the OKS, really.
The editor is web-based, and from the screenshot it looks like a Java applet. The TouchGraph applet is integrated with the editor. The engine has a Java API with several implementations. It has XTM import/export, full-text search, tolog support (!), and XMI import/export. Also has user rights management, versioning, and something he calls TMSL (Topic Maps Script Language).

Jakub Strychowski |
He also says the "remote" implementation has support for what he calls "distributed computing", which seems to be support for connecting multiple servers. Not sure exactly how or why, but I see JDBC and EJB on the slide. The "filtered" implementation uses the user rights support, so that a user can only see and modify what s/he has the rights to. The user rights are defined in the topic map.
TMSL is based on the Java grammar, but embeds constructs from TMQL and TMCL. Implemented with antlr. Supports most of Java, together with SELECT expressions from TMQL. I suppose this is what he called tolog above. Operations for accessing/modifying Topic Maps added. He shows an example, which uses tolog prefix declarations to access topic map constructs directly in the program, and also uses tolog queries directly in the program to produce an Object[][] array as the query result. Reminds me of the proposal that embedded SQL directly in Java code.
At this point I lost track, as I started fiddling with the photos. The rest seemed to be about an example application and the navigator. Sorry I missed it, but it should be in the paper anyway.
Pantau
The next speaker is Lars Heuer, talking about Pantau, which is a Python implementation of the TMRM. He starts with an introduction to TMRM, which I won't attempt to reproduce here. For those struggling to understand the TMRM I can recommend his slides, which were admirably clear. I hope they'll go up on the web somewhere.

Lars Heuer |
His thinking was that the best way to do a Topic Maps engine must be to implement Tau+ (the basis for TMRM), and then do TMDM in Tau+ so that he could support TMQL, XTM, etc etc He's using his own and Barta's TMDM-to-Tau+ mapping, which he's speaking about tomorrow. He does caution that a Tau+ implementation with a 1:1 TMDM mapping the result may not be efficient.
His conclusion: Tau+ is a good, elegant model, but should not be used as an API for the developer. More research needed on the TMDM-to-Tau+ mapping. A specialized TMDM engine might be more efficient. PanTau is currently a prototype, which needs more work before it will be released.
In the questions it emerged that he thought TMDM-in-Tau+ would be slow because the mapping is very voluminous. I asked if an approach like what I used in the Q model to compact the result of the mapping might work, and he said "yes"; this was one of the things he'd meant by saying the mapping needing more research.
A TM Application Framework
Naito-san is the next man out, with a talk on an application framework based on Topic Maps. He starts out with slides, then switches to a novel approach, a presentation based on a Vizigator view of a topic map. He shows himself as a topic, by way of introduction, then goes to his presentation (also a topic), and the table of contents (a set of topics for each section). Very cool. :)

Naito-san |
The foundation for his framework is both Topic Maps and RDF, combined with Published Subjects. He emphasizes the need for a protocol so different Topic Maps servers can connect to each other. He mentions both TMRAP and Kal's TopicMapster. The main functions of the framework are input, output, storage, and retrieval. Most of the detail on these is familiar, but some things were new: Topic Maps to PDF output, for example.
He's done work on measuring the semantic distance of topics in a topic map. He showed the maths briefly, but too quickly for me to pick it up. It'll be in the paper, I guess.
It seems he's taken ISO 12207 Software Life Cycle Process (SLCP) and created a topic map for it. He's then added the semantic distance and Bayesian network inference tools on top of it.
In the questions Alex Sigel brought up something I think was called "probabilistic Datalog", which is used in information retrieval. That sounded quite relevant, and interesting. I may need to do some digging on that.
After this we had lunch.
TMRAP 1.0
I was the first post-lunch speaker, with a talk on TMRAP 1.0. TMRAP is essentially a web service interface to a Topic Maps server, and provides operations to look up topics, retrieve query results, update the topic map, and listen to changes to topics of interest.
If you're interested I recommend Steve's presentation, Graham's TMRAP 0.2 specification, and my own paper. More detail on TMRAP 1.0 will become available when it's implemented in the OKS.
Topic Maps, Thesauri, and LDAP

Thomas Schwotzer |
Thomas Schwotzer (of jubik.de) followed with a talk on the use of Topic Maps on PDAs. Deployment on PDAs has special implications, like the components not always being online. He rejects UMTS and GPRS, as they cost money. A consequence is that each client must be autonomous. For shared vocabulary he relies on PSIs, but current practice in the use of PSIs is focused on centralized uses. This doesn't work for him. He wants a fully distributed PSI set, where each client only has parts of the full set.
What he's done is to use LDAP. He's created a thesaurus schema in LDAP, and then made XTM export tools, and tools which can import thesaurus data following his schema from XTM. LDAP is then used to distribute the actual information, and each concept gets a PSI by virtue of being an LDAP entry, since all LDAP entries are accessible via HTTP.
He then showed how he could use a web interface to search for a term in the thesaurus, export the subtree under that node to XTM, and then browse it with the TMNav browser.
Currently the implementation is in alpha stage, he says.
In the question session it emerged that there are no LDAP clients on the PDAs. They run Topic Maps.
Topic Maps Exchange in the Absence of Shared Vocabularies
This talk by Lutz Maicher. The scenario is: what happens when different people create different topics in different circumstances, without knowing about each other? (For some reasons all his examples seem to be pictures of moose. Why this is is not explained. :) In this case they will not use the same PSIs, simply because they don't know about each other. Lutz describes this as effectively being a P2P situation.
He's defined a means for measuring subject similarity, called Subject Similarity Measure (SIM). There is a defined procedure for computing this measure for a pair of topics. It seems to have progressed a bit from the first paper he did on this subject a while back.
The actual formula uses all properties of a topic, including associations, variant names, item identifiers, and so on. It gets pretty big. :) It appears to recurse up to the typing topics of each topic and compute similarity there, too. There is also a notion of string similarity which gives finer-grained answers than yes/no.
He's tested this on real topic maps, by creating a randomly pruned fragment around each topic. I didn't quite get the conclusions from this. There was something about 90% precision, which sounds good, but I'm not clear on how he arrived at it. Alex Sigel was critical of this, but in a case where Lutz had tried correlating a Japanese topic map with a German one. Personally, I'm impressed he even tried. :)
In the question session it emerged that there is an implementation of this, but it's not available. Only on his laptop, he said.
Topic Maps Modelling with ORM and UML
After the break, the first speaker is Are Gulbrandsen, of University of Oslo. He's comparing modelling of Topic Maps in ORM versus modelling with UML. He says people are using UML already, and he wanted to see if ORM could be a better alternative. He's hoping to stir discussion and feedback on this. Goal is to be able to generate a TMCL schema from an ORM model.
He's come up with a set of conventions for modelling Topic Maps in ORM. This came out as quite verbose, so he's done some modifications to true ORM in order to compact it. Scope turned out to be difficult, and not supported by UML or ORM. His solution was to use a textual notation for this, inspired by how LTM does this. His approach supports names, occurrences, associations, and scope. (At least.) In my opinion this looks like the beginnings of a good way to model Topic Maps graphically.
He then moved on to showing an example ontology from the Houston project. This is a Topic Maps system for the ICT control centre at the University of Oslo, used to quickly find necessary systems administration information. He showed the class hierarchy (in ORM), and emphasized that the modelling was more pragmatic than beautiful. Some of the subclasses exist only so different rules for these classes can be specified in the model.
The examples show how ORM supports not only laying out the basic structure of the ontology, but also specifiying constraints via the uniqueness constraints. This, somewhat surprisingly, also gives cardinality constraints.
He's used a set of well-established evaluation criteria for modelling approaches to compare ORM and UML:
- Expressivity
- He claims ORM has a richer set of extensions, but that both notations have extensions, and that OCL in UML goes beyond ORM again. With graphical notations, he says, the 80/20 principle has to be used. (Yes, definitely!)
- Clarity
- Of course very subjective. He claims ORM comes out better here, and has arguments to back it up. (See the paper, I can't type quickly enough!) He also uses a UML example, which definitely is not clear, then shows it again in ORM, which is a lot clearer.
- Semantic stability
- In UML, you often have to turn attributes into classes. This causes changes to ripple through the model, which is bad. ORM doesn't have attributes, which means this type of issue does not occur. (To me this seems a good argument; Topic Maps have something similar via reification.)
- Abstraction mechanisms
- These improve clarify by allowing detail to be removed in different views. He's going faster now, so I lost the rest.
His conclusion is that ORM can be used to model Topic Maps, and that it has advantages over UML. Of course, UML is better-known and more widely supported by tools. Not clear yet how well his proposed extension for scope is going to fit the ORM metamodel.
In the question session Steve asked how this would support n-ary associations. Are responded by showing a ready-made slide of this, so clearly he'd anticipated the question. The slide showed that this fits naturally into ORM, which definitely is a strength.
Using Topic Maps for Image Collections

Martin Leuenberger |
Martin Leuenberger is next, with a presentation on Topic Maps for organizing images. This was a project done for the pharmaceutical company Novartis, which wanted to organize an image collection. The images were actually about the construction of their new headquarters. It included not only photos, but also videos and drawings.
He lists three parts to the system: metadata schema, thesaurus, and topic map. The thesaurus is based on the Art & Architecture Thesaurus (AAT). Main branches: people, objects, activities, attributes, and setting. (Seems more like a faceted classification than a thesaurus to me.) I didn't quite get the other parts, unfortunately.
The system can be accessed via text-based search, and visual search. The latter works in terms of colour features and human-assigned visual criteria. Luminance seems to be one visual criterion. (Hmmm. Couldn't that be assigned automatically?) He shows search by a combination of profession, activity, and picture type, which seems very powerful. (Construction worker, rest, portrait: result is very good.) They also support browsing, which seems to be where the topic map comes in. (Not sure why it's not all in a topic map.)
In the question session I asked why it was not all done in the topic map, and he didn't seem to have considered this. He suggested we discuss it in the break instead. In the break I found myself deep in discussions with other people, and so we never got to it, unfortunately.
Generating Topic Maps from Real-time Speech Streams
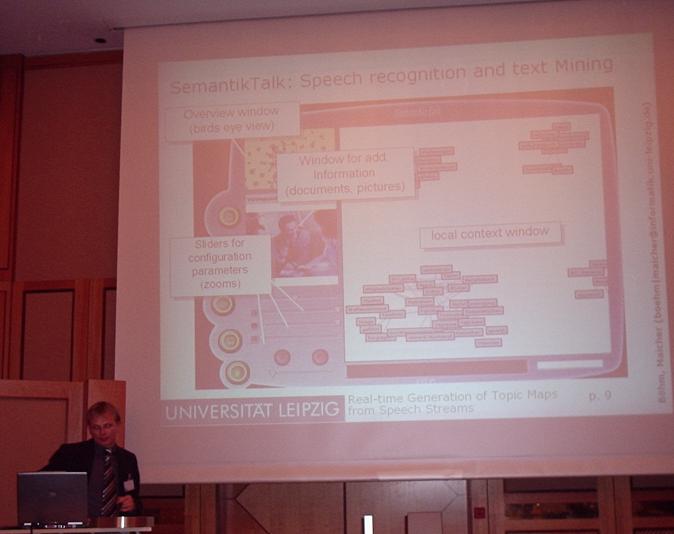
Karsten Böhm |
Lutz Maicher is covering this, together with Karsten Böhm. Again we see lots of moose, and this time they have names, as well as social problems ("Bernd needs a cow"). A difficulty here is to know what to consider as a legitimate subject, and secondarily when the same subject occurs at different times in the stream.
They use a system called Semantic Talk, which has speech recognition and text mining support. They also do visualization via TouchGraph. Semantic Talk supports RDF export. This probably explains the Omnigator screenshot I saw later. :)
One of the ideas here is to integrate the topic map from the current speech stream with topic maps from older speech streams, or even topic maps coming from other types of sources. It seems quite clear that this is related to the SIM from Maicher's previous talk, but I can't work out how they use it.
The associations are created by statistical means (based on mentions in nearness of time), so initially they have no labels. The input topic maps can contain background knowledge, such as existing associations, that allow you to label the associations.
Polyscopic Modelling with Topic Maps

Rolf Guescini |
Then follows Rolf Guescini, on behalf of himself, Dino Karabeg, and Tommy Nordeng. The motivation for polyscopic modelling is the problem of information overload. The main problem, as they see it, is that today most information has no over-arching structure organizing it. And the main problem is the lack of high-level information so that you can make sense of the low-level information, of which there is a lot. This requires a succession of more and more detailed views on the information.
The idea is that there are different "scopes", giving you different views of the information. He used the image of a mountain, where from the top you can see the big picture, and from different points you can see different views (or "scopes") emphasizing different parts of the same whole. Polyscopic presentation is hierarchical and modular. (Note that this says presentation; there is no limitation to hierarchies here.)
The methodology contains some criteria for modelling:
- Perspective
- There must be a view of the whole, in correct proportion, with nothing essential left obscure or hidden.
- Nourishment
- This relates to values, emotions, preferences, but I didn't catch how.
- Relevance
- Information must be prioritized according to the purpose that it needs to fulfil.
- Foundation
- Information must be reliable and verifiable (or proven).
The reason they're here, of course, is that they want to implement polyscopic modelling in Topic Maps. This is research-in-progress, so this part of the work is not complete yet. He showed some examples of approaches they'd tried. To me it looks like they're not quite there yet (but then that's what he said).
He then switches to showing an example application that embodies these principles. It's TM-driven, and based on the OKS. The start looks good, giving four high-level topics to choose between. After that he shows different levels of views on these topics, with more or fewer associations, longer/shorter texts, etc.
Subject-Centric IT in Local Government

Peter-Paul and Gabriel |
Peter-Paul Kruijsen from Morpheus (together with Gabriel Hopmans) talks about the ON-TOP project, a collaboration with BCT, a Dutch CMS vendor. Their goal is to integrate BCT's CORSA system with Topic Maps. CORSA is well-designed, but has very application-centric data, which makes it hard to find information. The challenge is to create a more intuitive interface, and ability to connect with other processes/organizations.
Morpheus wants to make the data subject-centric. Step 1 was up-conversion from database to topic map, using the Ontopia MapMaker tool. They built a user interface for creating the DB2TM mappings, based on the OKS Web Editor Framework (a screenshot was shown).
Step 2 is visualization of the conversion result. They have an Omnigator-like interface, where subject centric-ness is the key. User searches are supported. Again we get to see a nice-looking screenshot.
The third step is restrictions, that is, access control. This is done by annotating the ontology topics with information about who is allowed to see which parts. This makes it possible to view parts of topics of one topic type without showing sensitive information about these topics.
Step 4: restriction manager. This is basically a user interface where the administrators can define the restrictions, and also set up the actual behaviour of the browsing application. This is done with no actual programming. (Not clear whether this was in place.)
Step 5: Chaining. I think this means connecting to other applications. This requires PSIs. They are working on this, but are not done yet.
Further work: better search support, more data aggregation, integration with other applications besides just CORSA, and a fuller framework for the page/topic layout.
Open space session
The open space session was a sequence of short talks which people could sign up to do during the day on a flipchart. Each person got five minutes to present his/her idea, and this was followed by discussion, and then the next person.

Robert Cerny |
First out was Hendrik Thomas, who presented his topic map wiki project. This can be seen at topic-maps.org. It's an existing wiki system enhanced with XTM support and a graphical browser. Topics can be edited in XTM collaboratively, and there is versioning, etc. People were quite enthusiastic about this. I tried it myself a couple of days ago, and thought it was quite interesting. I've already added a new topic. :)
Then followed Robert Cerny, who has created a personal knowledge journal system. It's based on PHP and JavaScript, and looked very nice. He'd already entered all talks and presenters at the conference into the system. It's based on topics and associations, but his occurrences are slightly different from the standard ones. XTM export is still to come.
Alexander Sigel held a passionate talk about the need for a PSI registry, and really wanted people to help him out. There was vigourous discussion on the subject, and general agreement that this was needed, without anyone really stepping up to pay for it. The subject was eventually deferred to the evening social session.
Lutz Maicher went last, and presented his bibMap topic map, about Topic Maps research articles. He encouraged everyone to look at it and send him extensions.
That was it! I'm now leaving for the social event.
Similar posts
Meeting on ontology modelling
Today there was another meeting of the Topic Maps Users' Group on ontology modelling in Topic Maps
Read | 2006-09-26 20:50
ISO meeting in Atlanta, day 1
This is an unofficial report from the winter meeting of ISO JTC1 SC34
Read | 2005-11-12 19:30
TMRA 2007 — day 2
The first talk I attended was by Robert Barta on Knowledge-Oriented Middleware using Topic Maps (abstract)
Read | 2007-10-13 23:52
Comments
Bernard - 2005-10-06 20:12:18
Alex - 2005-10-07 01:40:30
Thanks for that report, Lars Marius. And I'm sorry I couldn't be there. Oh well.
Alexander Sigel - 2005-10-09 22:16:36
see comment on probabilistic datalog and tolog in my blog
Alexander Sigel - 2005-10-09 22:47:52
see preliminary comment on PSI registry in my research blog