Advances in active learning

Seagulls, Robin Hoods Bay |
I've come up with two improvements to the genetic algorithm with active learning since I first implemented it. One of them is the sort of thing that could make for a publishable research paper, but it's very likely that the idea has already been invented and published by somebody else. Which means I'm not very tempted to go through all the work of making a formal paper, only to have it rejected by reviewers as already known. Hence this blog post.
To recap quickly, the problem with the genetic algorithm is that it requires near-perfect test data to work. But anyone who can produce near-perfect test data has already pretty much solved the problem, and isn't really in need of help. Active learning solves this, by running without test data, and instead asking the user for the correct answer to the most informative examples. The most informative being those which the population disagree the most on. Dead simple, and, incredibly, it works.
However, I noticed quite quickly that it was not perfect. I would very often get questions that were very similar to questions I had already answered. That was annoying. As a user I could tell the machine was not asking the right questions, and so wasting my time and its own opportunities to learn.
Equivalence reasoning
In our specific case the algorithm is trying to work out how to tell which records are duplicates of other records, and it's asking me to label candidate pairs of records as either duplicates or not duplicates. Now let's say it asks me if A=B and then later if B=C, and I say "yes" in both cases. At this point, asking if B=A, or C=A, A=C, or C=B is all a waste of time. It's obviously true. Further, if the machine then asks if C=D, and I say "no", then it will follow that A!=D and B!=D.
If we can get the algorithm to perform this kind of reasoning on the answers it gets, we can avoid lots of redundant questions, and thus improve both the quality of results and the experience for the user. It will, for example, be possible to run the algorithm with a smaller population and fewer questions, and thus get good results faster with less effort.
Now, Duke already has a concept of a LinkDatabase, which performed some equivalence reasoning already. All I had to do was store the answers I got in the LinkDatabase, and improve the reasoning. Before asking about a pair, I could just ask the LinkDatabase if it could figure out the answer for that pair, and skip it if "yes". Piece of cake, although the actual reasoning algorithm was more work than you'd expect.
But how big is the effect? I did an experiment, running the Cityhotels problem 20 times with a population of 20, asking 5 questions per generation. Below are graphs of the performance with and without equivalence reasoning. As you can see, the impact is quite substantial. Without equivalence reasoning the algorithm can't really come up with any good solutions at all. With the reasoning we do pretty well. (If we up the population to 100 and ask 10 questions we can get an average after 100 generations of roughly 0.98, so there is room for improvement.)
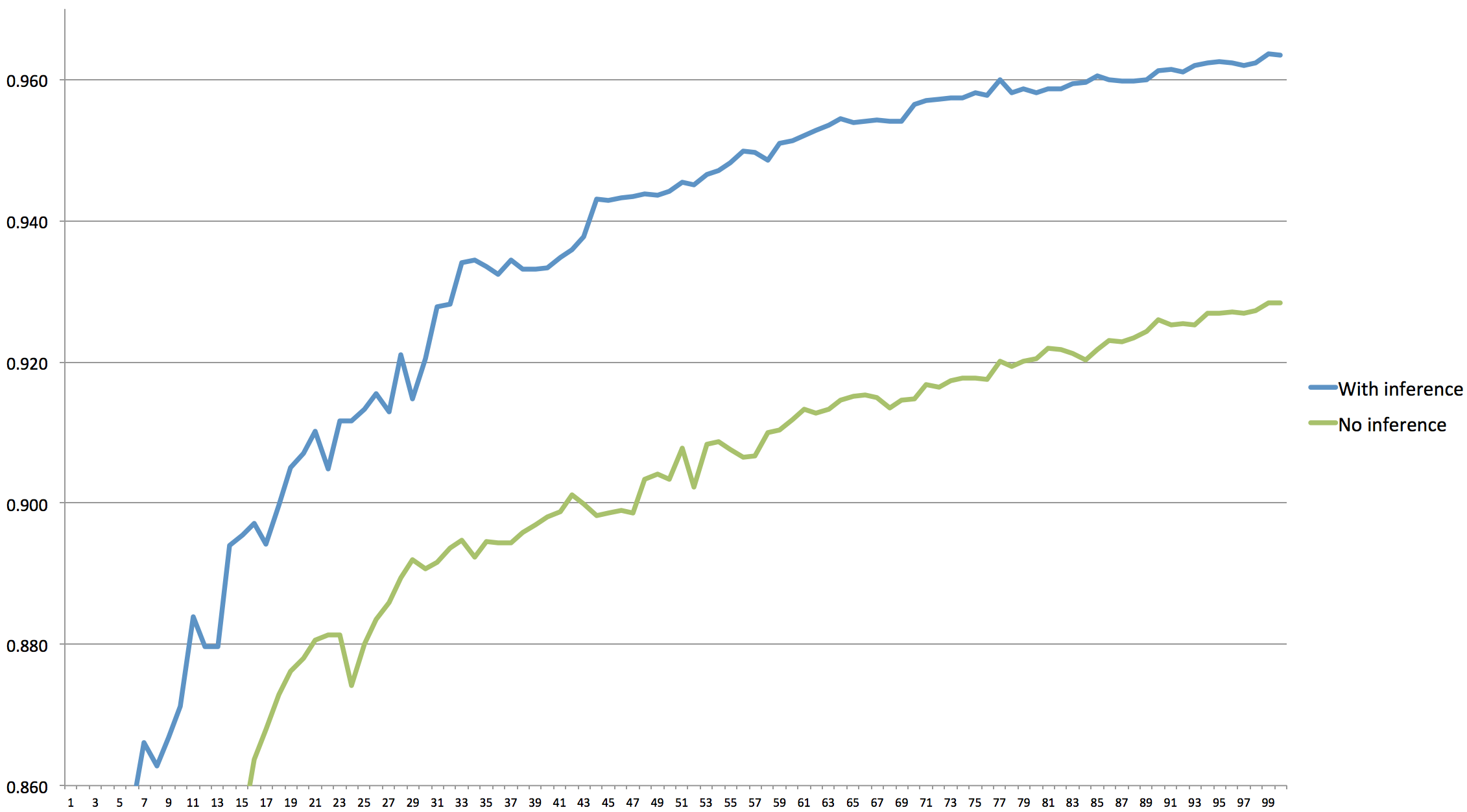
Plot of accuracy (f-number) |
Splitting the same way
This was all well and good, but I could tell that the system was still not asking an optimal set of questions. Very often it would ask first if A=B, and then if A=C. Typically, A and B would have relatively different data, which is why the question was worth asking, but B and C would have near-identical data. A real example from the experiment logs: first it asks whether 'blakemore' = 'blakemore hyde park' (the answer is yes). Then it asks exactly the same thing again. It looks like a bug in the equivalence reasoning, but while the two Blakemores are the same, the Blakemore Hyde Parks have different IDs.
A question is being wasted here, but it's far from clear how to detect that it's redundant. The pairs A=B and A=C are very similar, but how is the machine to know? We don't have any mechanism for comparing the two pairs (A, B) and (A, C). We do have mechanisms for comparing the actual records, but the trouble is that we're in the middle of a genetic algorithm, so we have 100 different ways of doing it and we don't know which ones are good.
I was stuck here for many months, pondering the problem now and then without finding any good answer. And then suddenly it struck me. We've chosen to ask about (A, B) and (A, C) beacuse they split the configurations into equally-sized sets of believers (yes, these are duplicates) and non-believers (no, they're not). The problem with these two pairs is that their believer/non-believer sets will be identical.
Answering "is A=B?" will punish those configurations that got it wrong. "Is A=C?" will have the same answer, and will punish exactly the same set of configurations. The algorithm is gaining very little from the second answer, both because there is little additional information, and because the evolutionary pressure from the second question will be distributed the same way.
The algorithm I came up with to handle this is really simple. What we want is to weed out these uninformative questions. So what we do is, when preparing to ask the user n questions, we pick out the 2n best candidate pairs in the usual way. Then, we choose from among those candidates the one whose believer set has the least worst overlap with an existing pair. That is, for each candidate, find the believer set. Go through all questions we've already asked and find the overlap in the believer sets (using the Jaccard index). The score for this candidate is the biggest overlap. Now pick the candidate with the lowest score.
Once the first question has been asked, we repeat the process from scratch, in case the next candidate has huge overlap with the question we just asked. Looking at logs of output from running the algorithm I can see that this is enough to weed out the dud questions. That sense of "but I just told you that!" is now gone.
But what about the performance? Performing another experiment and graphing the results in with the others we see that the outcome is another jump upward in performance. Particularly in the early phase. Eventually, the algorithm gathers enough information to figure it out anyway. However, if we reduce the number of questions even more that probably won't be true.
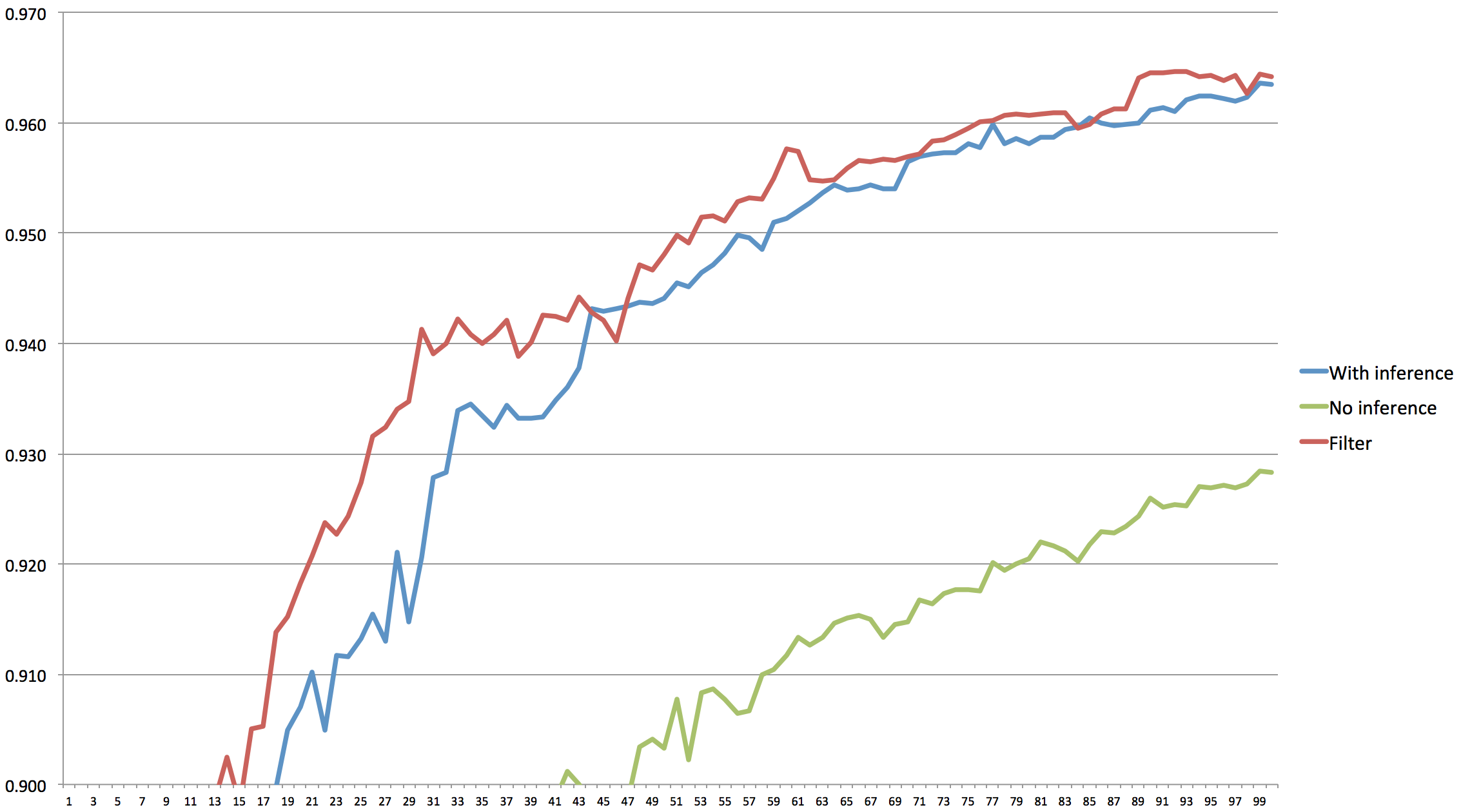
Plot of accuracy (f-number) |
What's interesting about this second trick is that it is so general. It applies to active learning regardless of domain, and has a simple and clear-cut mathematical definition that's closely tied to the basic approach of maximizing disagreement, and to correctly applying evolutionary pressure. Hence my belief that this would be publishable. It's also, once you think of it, kind of obvious. Hence my belief that it's already published. But it was fun, anyway.
Similar posts
Active learning, almost black magic
I've written Duke, an engine for figuring out which records represent the same thing
Read | 2013-10-20 13:03
Experiments in genetic programming
I made an engine called Duke that can automatically match records to see if they represent the same thing
Read | 2012-03-18 10:06
Bayesian identity resolution
Stian Danenbarger has been telling me for a while about entity resolution (as he and many others call it), or identity resolution (as Wikipedia calls it)
Read | 2011-02-11 13:23
Comments
Vern - 2018-02-18 18:33:50
I don't agree with your statement for this. "At this point, asking if B=A, or C=A, A=C, or C=B is all a waste of time." Asking if C=A and/or if A=C, are questions to see if you can make the connection, to the "obvious" not in evidence ;-) Like a control question.