Active learning, almost black magic

Waiting for the tide, Robin Hoods Bay |
I've written Duke, an engine for figuring out which records represent the same thing. It works fine, but people find it difficult to configure correctly, which is not so strange. Getting the configurations right requires estimating probabilities and choosing between comparators like Levenshtein, Jaro-Winkler, and Dice coefficient. Can we get the computer to do something people cannot? It sounds like black magic, but it's actually pretty simple.
I implemented a genetic algorithm that can set up a good configuration automatically. The genetic algorithm works by making lots of configurations, then removing the worst and making more of the best. The configurations that are kept are tweaked randomly, and the process is repeated over and over again. It's dead simple, but it works fine. The problem is: how is the algorithm to know which configurations are the best? The obvious solution is to have test data that tells you which records should be linked, and which ones should not be linked.
But that leaves us with a bootstrapping problem. If you can create a set of test data big enough for this to work, and find all the correct links in that set, then you're fine. But how do you find all the links? You can use Duke, but if you can set up Duke well enough to do that you don't need the genetic algorithm. Can you do it in other ways? Maybe, but that's hard work, quite possibly harder than just battling through the difficulties and creating a configuration.
So, what to do? For a year or so I was stuck here. I had something that worked, but it wasn't really useful to anyone.
Then I came across a paper where Axel Ngonga described how to solve this problem with active learning. Basically, the idea is to pick some record pairs that perhaps should be linked, and ask the user whether they should be linked or not. There's an enormous number of pairs we could ask the user about, but most of these pairs provide very little information. The trick is to select those pairs which teach the algorithm the most.
How to pick those pairs? Axel's solution is simple and ingenious: pick those on which the configurations disagree the most. If you have 100 configurations in your genetic population, pick those pairs which half of the configurations think should be linked and half the configurations think shouldn't be linked. Or as close to half as you can find. That's it. That's the whole idea.
What's fascinating is that this almost ridiculously simple solution actually works. If I ask the user 10 questions per generation that's actually enough to solve the problem. Of course, if you run it to the end, that means answering 1000 questions, which gets pretty tedious. But we don't need to do that. We can skip asking questions after some generations, and stop before we get to 100. That way we can get down to, say, 100 questions.
To make this a little more concrete, let's look at some real-world examples.

On the beach, Robin Hoods Bay |
Linking countries
Let's start with the linking countries example. Here we're trying to link a country list from DBpedia with one from Mondial. We have the names of the countries, their areas, and the names of the capitals. The data quality is less than perfect, so the matching is non-trivial. Running in sparse mode, we ask questions after the 1st, 2nd, 4th, 6th, 8th, 10th, 14th, 18th, 22nd generation, and so on.
Looking at the output as it floats past we can see that the algorithm quickly figures out that it must use numeric comparison of the area of the countries, and a little later it picks Levenshtein for the name comparison. For comparing capitals it often uses exact comparison, or one of the key-based comparators (like Soundex). It quickly puts a lot of emphasis on the area, much more than you'd expect, but that actually works well. So just by eyeballing the output you can see that the algorithm is working.
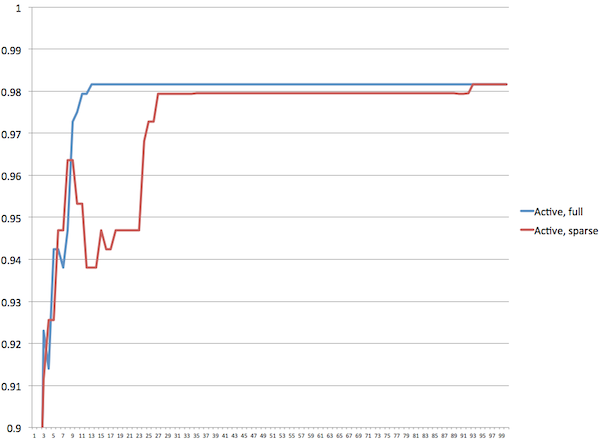
Full and sparse mode |
Looking at the graph we can see clearly that the performance of the configuration the algorithm thinks is best shoots to the top almost immediately, and stays there. In full mode we solve the problem in about 15 generations, and in sparse mode we do it in about 30.
The average score of the configurations in the population behaves much the same way, and the average deviation between the algorithm's assessment of the score of the configurations and the true score nosedives quickly and stays low.
Remember that the algorithm only knows what the user has told it explicitly, so it can only estimate the scores of the various configurations. To produce these graphs I've cheated and used known perfect test data. Looking at the output I can see that a number of times the algorithm has found configurations that are better than what it reports as the best configuration. Lacking accurate training data, that's inevitable.
This example is almost too easy, though, so let's try something a little harder.
Cityhotels.com
The Cityhotels.com hotel booking site gets hotel data from three different sources, which means they get most hotels three times. There are no common IDs, so they use Duke to deduplicate the hotels, using the following properties:
- Hotel name,
- Address (spread over 4 attributes),
- Stars (as in "a four-star hotel"),
- Email,
- Phone,
- Fax,
- Geo-coordinates,
- Region (basically city code),
- Source (ie: which of the three sources).
This is a tricky problem. We're deduplicating, which means we have to very, very carefully weed true duplicates from merely similar hotels. We also have a lot of properties, which need to be compared in very specific ways. For example, geo-coordinates should be compared with the comparator for that, whereas source should be different, and so on. The data is also fairly noisy, and on top of that, quite a few of these properties don't really contain much useful information.
We have correct test data for five cities, so we can run the genetic algorithm on those data, and use the test data to evaluate how it does. With 3648 hotels in the data set, running the whole thing takes a while. Below I've graphed the accuracy of the best configuration (that is, the one the algorithm thinks is best), and the average of the population. Note where the best drops below the average, those are situations where the algorithm picks as "best" a configuration that in reality performs below the average.
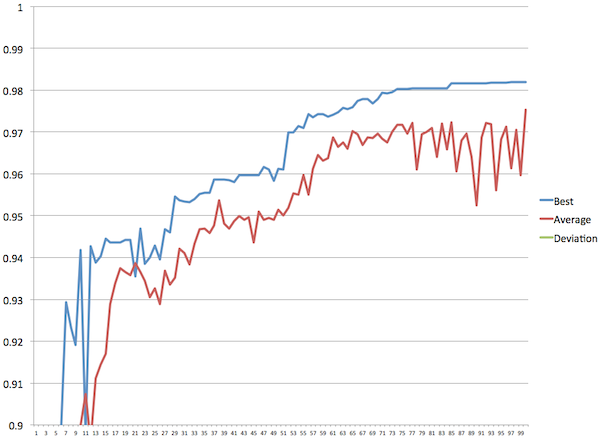
Active learning, 10 questions per generation |
After 10 generations the algorithm has achieved reasonable performance, with 94% accuracy. It goes up and down a little, but makes steady progress, and by generation 54 we're above 97% accuracy. The initial flapping up and down is caused by the algorithm not having enough information, so it picks the wrong configurations to reproduce, because it has an inaccurate idea of which ones are the best. After it's asked about 100-140 questions, it's learned enough that things settle down from there on.
If we look at the best configuration in each generation, progress looks like this:
- Generation 10: It doesn't really know what it's doing yet. None of the choices make that much sense.
- Generation 20: It's worked out that stars is mildly useful for finding out that hotels are different, but shouldn't be used for anything else. Comparisons for phone, fax, and email are pretty good. It's also worked out how to compare geo-coordinates.
- Generation 30: It's learned to use q-grams for names, which really is the right choice. It's also learned that ADDRESS1 is the most important address part. It's worked out that hotels in different regions are different. And it's worked out that hotels from the same source probably aren't duplicates.
- Generation 40: It's just tweaking the details now, since it's got the basic approach correct.
From the graph we can see that asking a little more than 500 questions is enough to give us a very good result, but if we keep going it gets even better. So the question becomes, how many questions do we really need to ask? Below I've graphed four different experiments against one another. You see results for passive mode (where we have a complete set of correct answers), active with 10 questions per generation, 5 questions, and 1 question. It shows clearly that with fewer questions, the quality of results goes down.
Somewhat surprisingly, the active mode with 10 questions per generation does better than passive mode after 70 generations. This is probably just luck, since these are graphs from single runs. What it does mean is that if you're willing to answer 700-1000 questions you can get results with active learning that are just as good as those you get in passive mode.
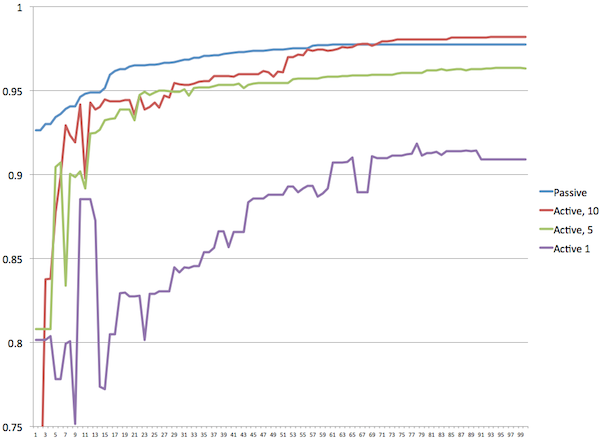
Four different approaches |
Can we improve on that by being more clever about which questions we ask? Axel's most recent paper shows that it is possible. He uses some fairly esoteric maths to do it, so for the time being I've held off from implementing his approach directly. I intend to explore different approaches, and also to learn from feedback from people who try out the basic algorithm on real-world problems.
Similar posts
Advances in active learning
I've come up with two improvements to the genetic algorithm with active learning since I first implemented it
Read | 2014-02-23 20:57
Experiments in genetic programming
I made an engine called Duke that can automatically match records to see if they represent the same thing
Read | 2012-03-18 10:06
Impressions from Strata London 2013
The first thing that struck me about the conference was that it had to be a fairly new conference
Read | 2013-11-20 08:44
Comments
maf88_ - 2013-10-20 10:10:33
Cool! Thanks for sharing.
dcd - 2013-10-20 15:40:04
This is a clear, simple explanation and use case for genetic programming. Knowing only a little about it before, this makes me want to try your programs to learn more. In addition, the problem of finding duplicate records in data sets is not a problem often thought about.
Thanks for posting.
Nick Bennett - 2013-10-21 11:08:07
Fantastic! A couple months ago I was asked to help with a task of matching data between 3 different data sources to be used in some academic research, and I made a fledgling attempt at it before deciding it was more complex than I originally thought. Your Duke program and this code is perfectly suited for the task!
Jonathan - 2013-10-21 14:33:41
Is there code or sudo code for a simple active learning library like this in Java or C++?
Lars Marius - 2013-10-21 14:45:04
@Jonathan: That's a good question. My own code is here http://code.google.com/p/duke/source/browse/src/main/java/no/priv/garshol/duke/genetic/
Easier-to-read Python prototypes are here: http://code.google.com/p/duke/source/browse/scripts/
There's a Java package here: http://jgap.sourceforge.net/
I don't really know. The basic idea was so simple I didn't bother with any framework, and simply wrote it myself. Once you understand the idea you don't really need anything more. My previous blog post has the basics on how the genetic algorithm works, and with the Python code in that it may be all you need: http://www.garshol.priv.no/blog/225.html
alex bloom - 2016-04-20 23:10:24
yet another great post by Lars that clearly explains the concept of active learning and presents the performance comparison between the passive and active modes